Statemachine example in stwo
this statemachine example has component with different degrees:
component file
StateTRansitionEval is the evaluation function, coordinate mark the number of the Eval
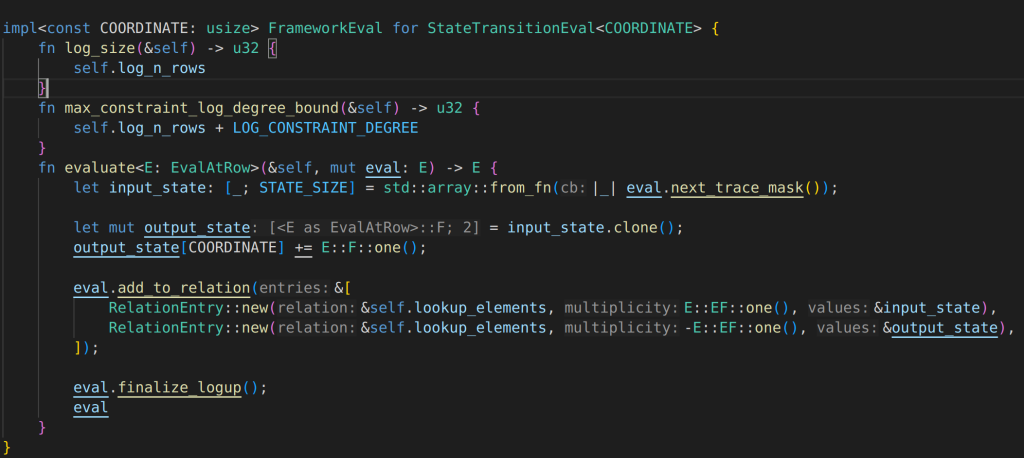
statemachine 0 has just two numbers, the mix_into put these numbers in to channel
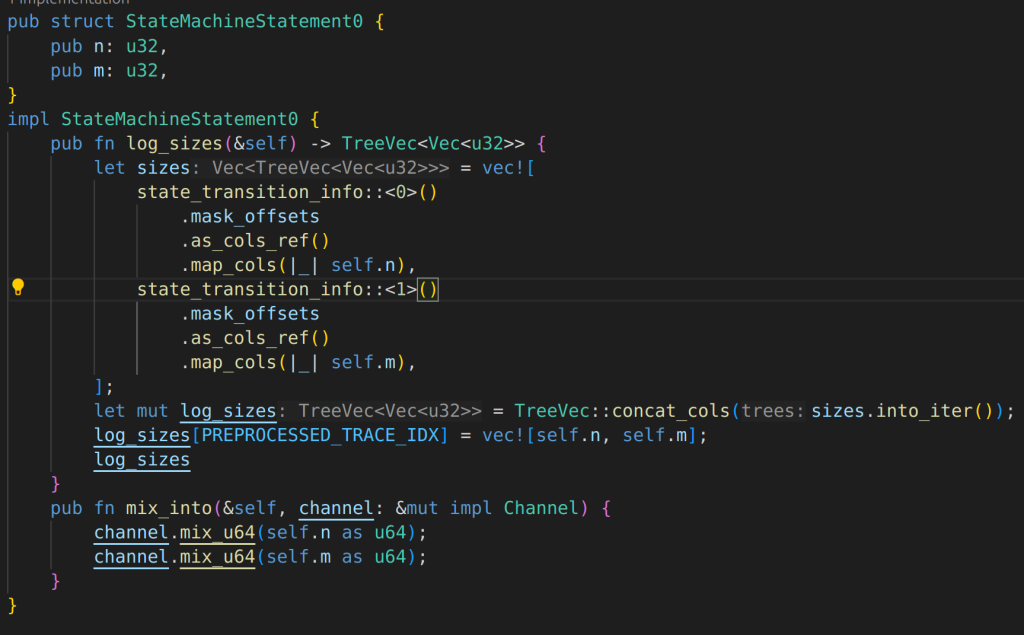
statemachine 1 aslo implement the mix_into function, and mix all its field elements into channel
question: does the mix_into function always need to take all the element of statementmachine (equivalent to circuit information) into channel?
one step back to internal code, the FriProver in stwo specifies that it is able to do batched commitment that handles multiple mixed-degree polynomials, each evaluated over domains of varying sizes.
there are some tests code in this file might be helpful to show how to prove commitment with varying sizes (but the tests are only about FRI commitments, not complete STARK prover)
conclusion after finishing implementation: no need to check FriProver, just create component for each size of columns.
Q1: Does stwo needs to create individual component for different size? yes
Understanding of statemachine example, in detail
run test in mod.rs file, using this command:
cargo test --package stwo-prover --lib -- examples::state_machine::tests::test_state_machine_prove --exact --show-output Prove_state_machine function in mod.rs:
initialize the statue, it is
Initial state: [M31(0), M31(0)] The parameters at the beginning are set to be:
x_axis_log_rows: 8,
y_axis_log_rows: 7
x_row: 34
y_row: 56
state changes:
Initial state: [M31(0), M31(0)]
Intermediate state: [M31(34), M31(0)]
Final state: [M31(34), M31(56)] pre-processed columns have different length? Yes!
preprocessed_columns: [IsFirst(8), IsFirst(7)]How the trace looks like?
Preprocessed trace:
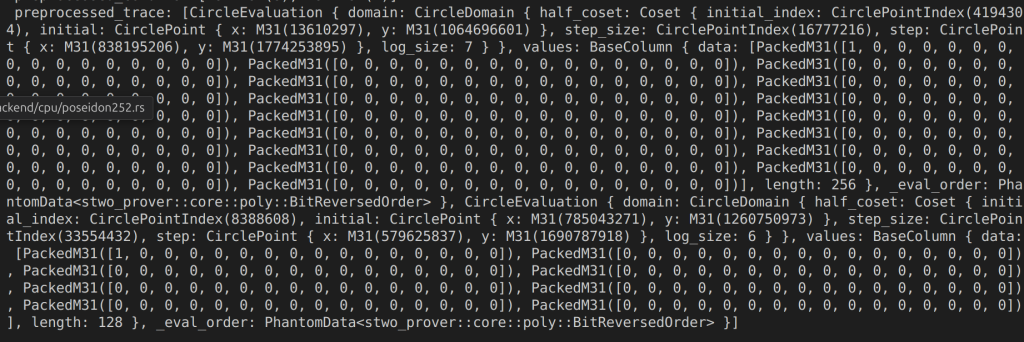
The figure above shows two pre-processed cols, they are all generated by IsFirst, this function IsFirst(log_length)
pre-processed col 0: 1,….,0 with length 256, \(2^8\)
pre-processed col 1: 1,….,0 with length 128, \(2^7\)
(remember the log size showed above is the half coset size)
two pre-processed traces are committed use tree_builder directly.
Witness traces
there are two witness traces: trace_op0 and trace_op1, also have length 256 and 128
trace_op0 has two cols of length [8,8]
[
CircleEvaluation {
domain: CircleDomain {
half_coset: Coset {
initial_index: CirclePointIndex(4194304),
initial: CirclePoint {
x: M31(13610297),
y: M31(1064696601),
},
step_size: CirclePointIndex(16777216),
step: CirclePoint {
x: M31(838195206),
y: M31(1774253895),
},
log_size: 7,
},
},
values: BaseColumn {
data: [
...
],
length: 256,
},
_eval_order: PhantomData<stwo_prover::core::poly::BitReversedOrder>,
},
CircleEvaluation {
domain: CircleDomain {
half_coset: Coset {
initial_index: CirclePointIndex(4194304),
initial: CirclePoint {
x: M31(13610297),
y: M31(1064696601),
},
step_size: CirclePointIndex(16777216),
step: CirclePoint {
x: M31(838195206),
y: M31(1774253895),
},
log_size: 7,
},
},
values: BaseColumn {
data: [
...
],
length: 256,
},
_eval_order: PhantomData<stwo_prover::core::poly::BitReversedOrder>,
},
]
trace_op1 has two cols, of length [7,7]
Interaction traces
interaction_trace_op0 has 4 cols of length [8,8,8,8]
interaction_trace_op0 has 4 cols of length [7,7,7,7]
Log size function of the state machine
this function:

I don’t quite understand it, but the outputs are:
log_sizes before get preprocessed trace index: TreeVec([[], [8, 8, 7, 7], [8, 8, 8, 8, 7, 7, 7, 7]])
log_sizes after get preprocessed trace index: TreeVec([[8, 7], [8, 8, 7, 7], [8, 8, 8, 8, 7, 7, 7, 7]])the function return a vec with 3 elements, each element itself is a vec, contains the length of the preprocess cols, witness cols, interaction cols.
it seems the length of the cols doesn’t matter, they get committed directly

The parameter in the CommitmentSchemeVerifier: proof.commitments
for verification, there are these steps:
- create hash channel
- create commitmentSchemeVerifier, it needs to commit to the pre-processed cols, witness cols, and interaction cols if have.
- use verify function
I think I didn’t do the hash channel correctly. now the function is like this:
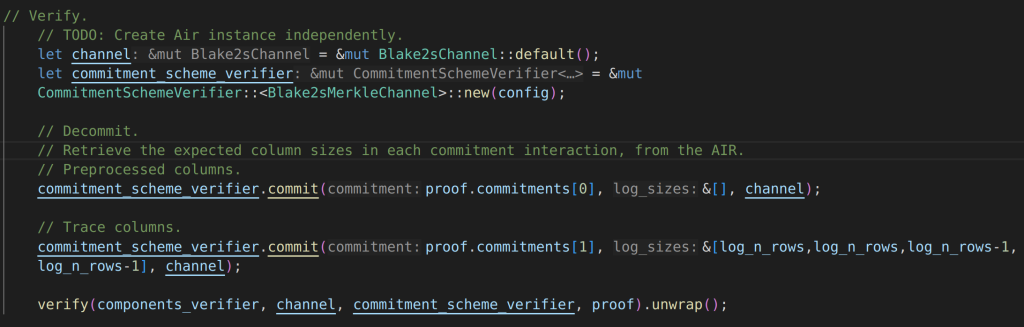
How state machine example traits hash transcripts?
after finishing implementation: no need to care til now, need to check when talk about challenger
Apply it to powdr
question 1:
for multi machines, should I create one component for each machine or should I create one component for all the constraint.
one for each machine.
In the state machine example, the multi component is used for different state, which more like proving the same thing but in different stage. so feel like I should get one component, and then when I need to do different stage to prove, then I can use more components.
because stwo by default allows cols with different length
and for powdr, it is not the different machine can use the same evaluation function, each machine has its own constraints, they need their own evaluation function.
first step:
make commitment with variant size available, constant col first.
despite the cols need to be in descending order, let firstly make it work and put into the prover to let it panic
The problem happen in initializing PowdrEval when creating component, it needs to have a single size and namespace of analyzed, while the analyzed passed to the PowdrEval::new is multi-sized.
PowdrEval needs split as well
so, this split should be in the component level or inside the PowdrEval?
it depends on how stwo handle cols with variant sizes, does it create component for each size? No!
for constant column, the proving key already group the columns with the same size. the stark proving key has this data structure:
pub struct StarkProvingKey<B: Backend> {
pub preprocessed: Option<BTreeMap<String, TableProvingKeyCollection<B>>>,
}the string above is the name space, the table proving key group the columns with same size, and specify the size
pub type TableProvingKeyCollection<B> = BTreeMap<usize, TableProvingKey<B>>;In plonky3, this separation is done by this code

namely, in the beginning of the prove function, witness are divided into group of machine. stwo needs this as well
test command for stwo in powdr
cargo test --package powdr-pipeline --test pil --features stwo -- stwo_different_degrees --exact --show-output